Introduction
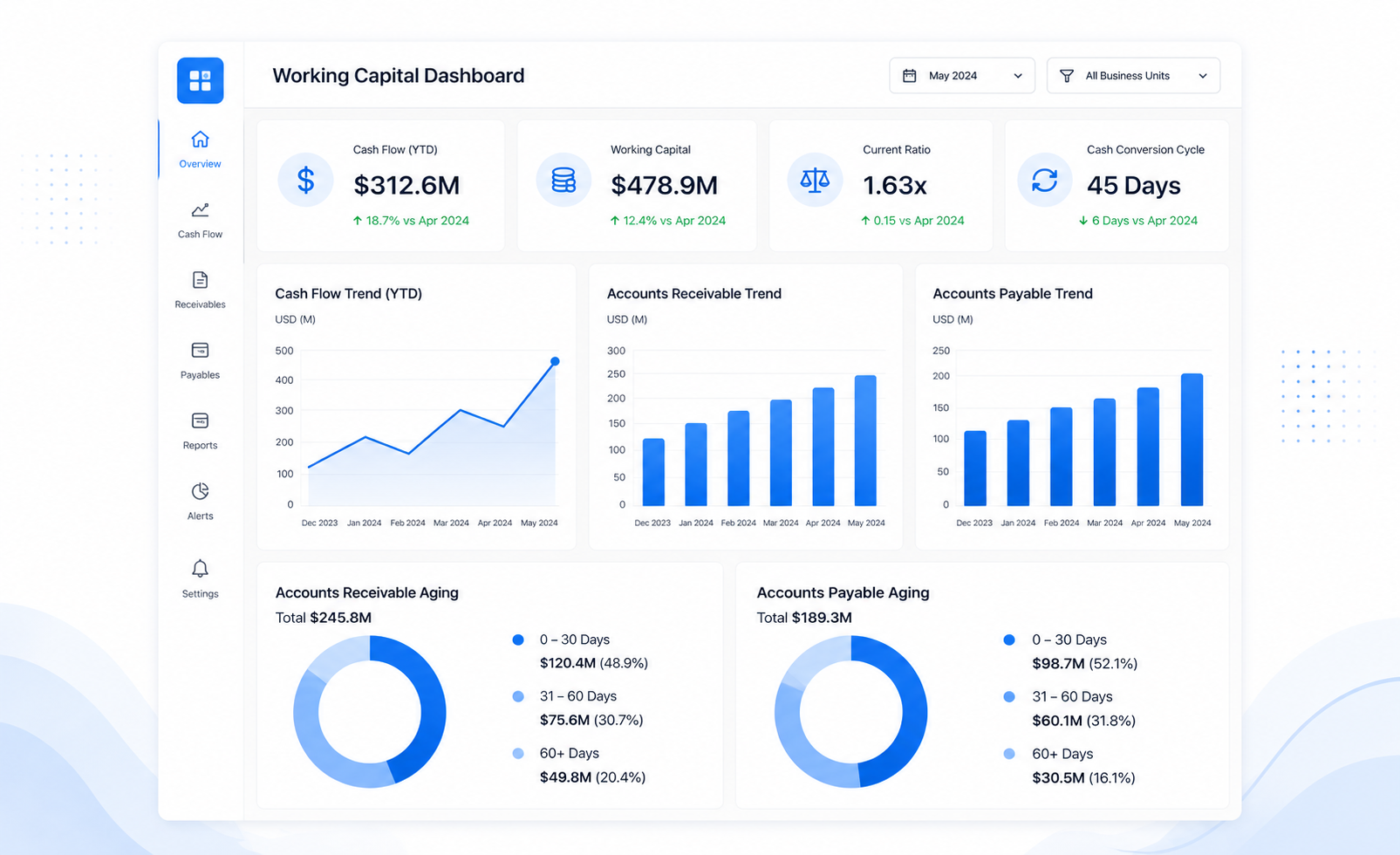
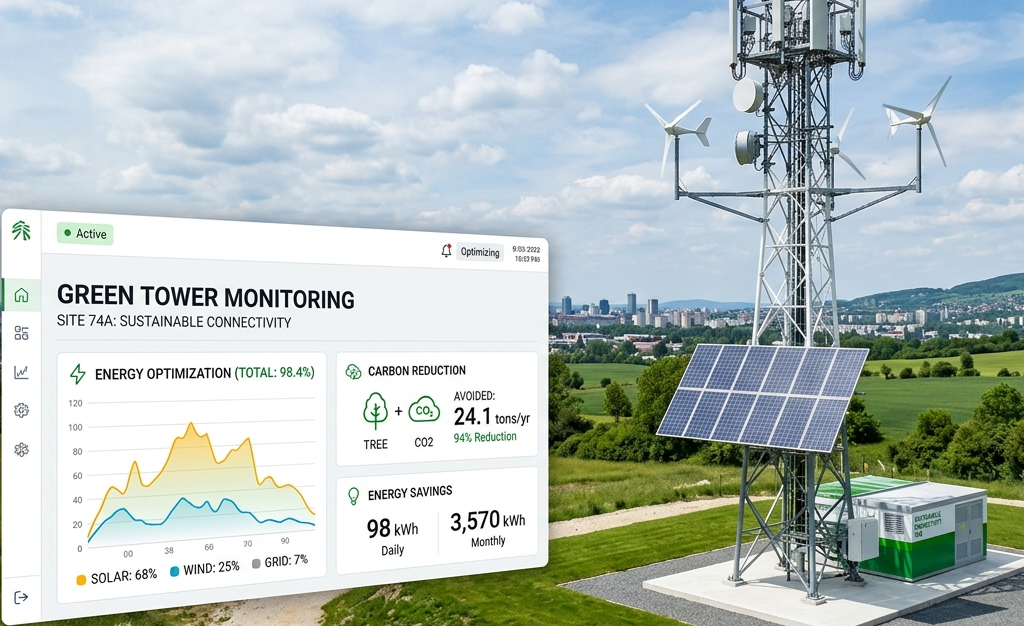
Modern energy ecosystems require intelligent orchestration of multiple energy sources, storage systems, and grid interactions. Traditional systems lack the flexibility to manage decentralized and hybrid energy environments. This case study highlights how a Digital Twin–driven energy management platform enabled real-time control, optimization, and scalability for a complex urban microgrid.
Customer
A Middle East–based renewable energy and infrastructure organization managing distributed energy assets.
Business Objective
- Enable real-time control of decentralized energy assets
- Optimize energy usage and storage across microgrid
- Improve grid resilience and independence
- Build scalable energy management architecture
Scope of Services
- Development of centralized energy management platform
- Integration of solar, battery storage, and grid systems
- Real-time monitoring and control of energy assets
- Dashboard and analytics implementation
- Multi-site energy optimization enablement
Technology Used
- Digital Twin–enabled energy management system
- SCADA + EMS platforms
- Real-time data ingestion and analytics
- IoT sensors and distributed energy integration
- Cloud-enabled scalable architecture
Key Challenges Addressed
- Managing decentralized and multi-source energy systems
- Integrating diverse hardware and protocols
- Ensuring real-time control and optimization
- Handling urban infrastructure constraints
Benefits
- Unified control across energy assets
- Improved energy optimization and efficiency
- Scalable and flexible architecture
- Enhanced operational visibility
Impact
- Real-time control of hybrid energy systems
- Ability to operate independently from main grid for limited duration
- Improved energy utilization and grid stability